|
很多时候,我们希望可以快速了解某些知识的基本情况,在深度学习中,我们更应该如此,然后知道我们需要在哪些方面注意。
本文在一片文章之中,教你设计一个在caffe中利用深度网络进行手写数字识别,让你快速了解某些重点知识。
所有程序我全部测试运行,没有问题。最重要的是,本文开篇即有一个本文学习的内功心法,以帮助大家快速进入状态。
几乎所有代码,我都进行了注释。我也是小白,刚刚开始,相信适合和我一样的初学者。
正所谓怕什么真理无穷,进一步有进一步的欢喜。祝愿各位早日获得想要的知识。
本文运行环境
Ubuntu16.04系统,配置好conda2,caffe,pycharm,python2.7,opencv
CPU
pycharm已经导入caffe,以及OS,numpy等必要的库
整体架构(内功心法篇)
建议按照我的思维导图进行阅读文件,因为我的笔记大部分是按照这个顺序的,而经常在第一次出现时记录比较详细,后面的可能不记录,也有可能是复制黏贴,所以解释可能不好。
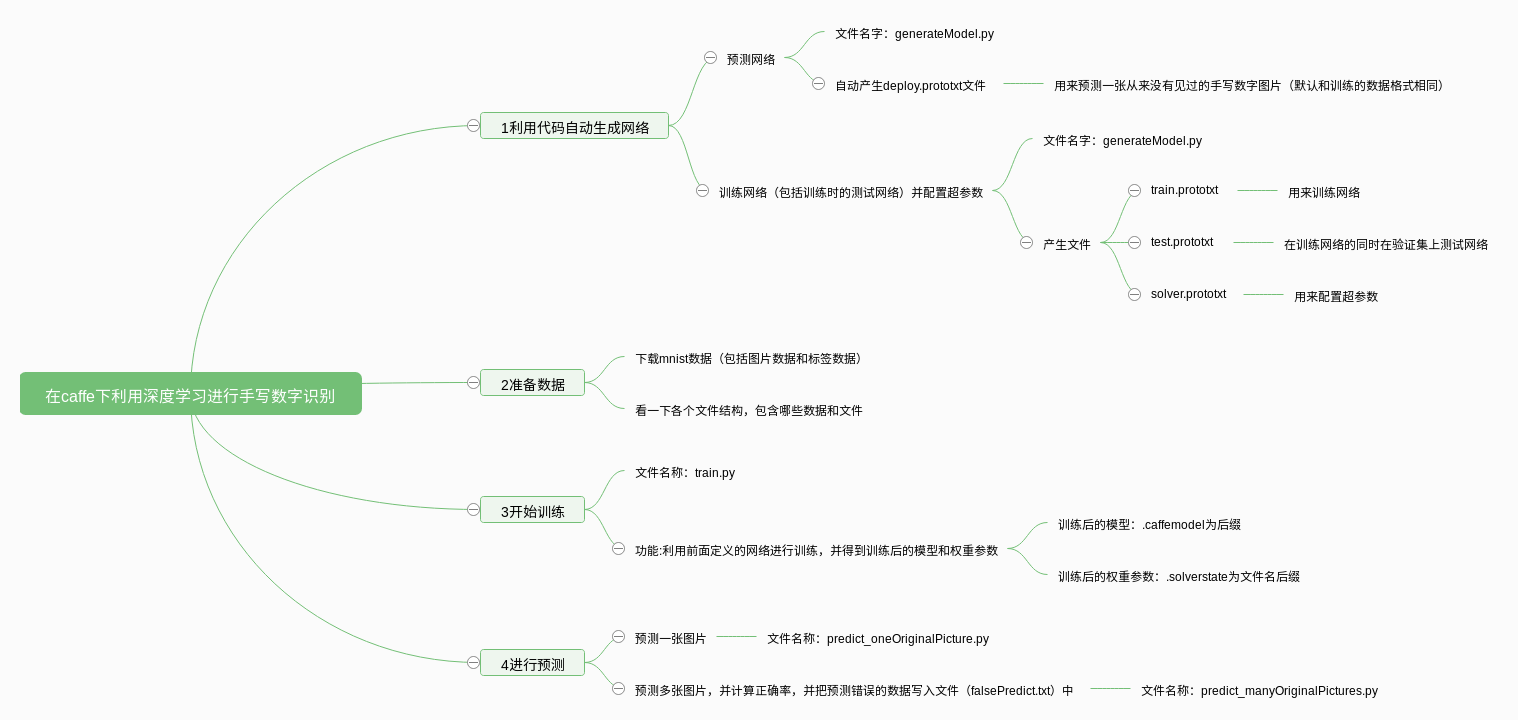
利用代码产生预测网络
# -*- coding: UTF-8 -*-
# 2018年06月02日12:59:57
# 于北京
# 2018年06月08日21:19:28 增加os库,用于更方便路径的设置
# 利用代码产生预测模型文件(预测模型也可以直接写成文本文件)
# 有时候,也可以直接下载别人写好的网络,如VGG等
# 输出文件名称:deploy.prototxt(路径名称在本程序中,可以根据实际需要进行修改)
import caffe
import os
# 定义一个输出预测模型的函数
def creat_deploy():
net = caffe.NetSpec()
# 调用caffe的方法用于生成一个网络框架.
net.conv1 = caffe.layers.Convolution(bottom = 'data', kernel_size = 5, num_output = 20,
weight_filler = dict(type = 'xavier'))
# net.conv1表示创建卷积层conv1,conv1层的名字,虽然可以随意指定,但是通常由层的类型+标号表示。
# caffe.layers.Convolution表示创建的层为Convolution(即卷积层),这就是创建层卷积层的方法。
# bottom表示输入数据,数据格式为data(适用于LevelDB或LMDB数据)(而对于HDF5文件,数据类型则是)
# kernal_size指的是卷积层的大小,即5*5的卷积层
# num_output表示卷积核的数量,也就是特征图的个数
# weight_filler表示权重的初始化,type='xvaier'指采用xvaier算法来进行初始化,这个方法有一个较好的效果。
# dict表示字典的创建,因为weight_filler有很多参数,这里需要转变成字典格式。
net.pool1 = caffe.layers.Pooling(net.conv1, kernel_size = 2, stride = 2,
pool = caffe.params.Pooling.MAX)
# pool1表示这是第一个池化层,也是层的名字。
# caffe.layers.Pooling表示利用这个方法创件一个池化层。
# net.convl表示输入,也就是前面一层的输出数据。注意到每一层的输出数据和层的名字相同
# 这里的核为2*2。
# stride表示步长,一般来说,池化层的步长都为2,可以将数据量降低到原有的四分之一。
# caffe.params.Pooling.Max表示利用最大值池化的方法。
# 一般来讲,池化层的特征图与输入相同
net.conv2 = caffe.layers.Convolution(net.pool1, kernel_size = 5, num_output = 50,
weight_filler = dict(type = 'xavier'))
# 输入为上一层池化层的输出,if net.pool1:
# 卷积核为5*5大小。实际上,现在一般采用较小卷积核(一般都是3*3,
# 通常来讲,多层小卷积核和浅层大卷积核参数数量相差很多,即使感受视野一样)
net.pool2 = caffe.layers.Pooling(net.conv2, kernel_size = 2, stride = 2,
pool = caffe.params.Pooling.MAX)
# 创建池化层pool2
net.fc1 = caffe.layers.InnerProduct(net.pool2, num_output = 500,
weight_filler = dict(type = 'xavier'))
# 创建全连接层:net.fc1,其中fc是full connect的首字母。
# 注意到全连接层的创建方式是InnerProduct,实际上,全连接层就是最原始的神经网络的连接方式
# 最原始的连接方式就可以通过向量内积来计算
net.relu1 = caffe.layers.ReLU(net.fc1, in_place = True)
# 创建激活层,relu是激活函数的一种,这里利用caffe.layers.ReLU方法来创建
# 输入为net.fc1,一般来说第一个参数为输入,输出和这层的名字相同。
# in_place可以节省内存和显存。
net.score = caffe.layers.InnerProduct(net.relu1, num_output = 10,
weight_filler = dict(type = 'xavier'))
# 创建评价函数,名字为net.score,和全连接层的创建方法,都是InnerProduct。
# 利用num_output来改变输出特征图的大小,这里的10表示输出有10类,表示十个数字
net.prob = caffe.layers.Softmax(net.score)
# 进行softmax操作,输出图片被预测为每个数字的概率,层的名字为prob
# 利用caffe.layers.Softmax方法创建
return net.to_proto()
# 上述创建好的格式存于数据成员net.to_proto中
# 定义一个想文件中写预测模型的函数
def write_net(deploy_proto):
#写入deploy.proto文件
with open(deploy_proto, 'w') as f:
# 注意利用with as的方法可以自动清理内存和捕捉异常.一定要常用.
# 这里将指定的文件打开,并将句柄给f.利用f就可以操作这个文件
#对数据进行描述
f.write('input:"data"\n')
# 表示输入的数据类型
f.write('input_dim:1\n')
f.write('input_dim:3\n')
f.write('input_dim:28\n')
f.write('input_dim:28\n')
# 以上四行分别表示数据的格式,即caffe中blob的格式.
# 1表示输入一个数据
# 3表示输入彩图,有rgb三个通道的数据
# 两个28表示图片的大小为28*28.
# 注意\n表示换行,之一斜线的方向,这是python中的转义字符
f.write(str(creat_deploy()))
# 将预测模型写入文件,调用了写模型的函数
if __name__ == '__main__':
current_root = os.getcwd()
my_project_root = current_root
# 项目路径
deploy_proto = my_project_root + "deploy.prototxt"
# 输出的数据名称(包含绝对路径)
write_net(deploy_proto)
# 调用函数写预测模型
print('输出预测模型成功')
# 打印输出成功,是人机交互,有一定的作用.
利用代码生成训练网络,测试网络和超参数文件等
# -*- coding: UTF-8 -*-
# 生成以下三个文件
# train.prototxt 这是训练的模型
# test.prototxt 这是训练时测试的模型
# solver.prototxt文件 这是训练模型的配置文件
# 2018年06月02日15:56:00 首次注释 于北京昌平
# 2018年06月08日20:59:22 修改路径 于北京昌平
# 请将下载好的mnist数据文件夹放在当前环境目录下
# 否则请自行设置最后的主文件main函数中的位置,注意只需要改写当前绝对路径后面的部分
import caffe
import os
# 创建网络模型文件的函数
def create_net(img_list, batch_size, include_acc=False):
net = caffe.NetSpec()
# 生成网络框架,这是caffe的函数
#ImageData数据层
net.data, net.labels = caffe.layers.ImageData(batch_size = batch_size,
source = img_list,
transform_param = dict(scale = 1./255),
ntop = 2)
# 创建数据和标签层,用来输入数据.利用caffe.layers.ImageData方法来创建
# batch_size是指每次运行的数据量,也就是每次迭代使用的图片数量.
# source表示图像文件的名字,每一行表示一个图像,包括像素值和label
# transform_param表示将像素值进行变换,这里用scale表示进行尺度变换,将每个像素值除以255,变换到0到1之间
# ntop表示输入的数据种类,2就表示有两个,一个是data,一个是label(这个还需要验证),数据在等号前已经说明了
# 当只有一个输入是,可以用top = conv1来赋值
# 注意数据的输入有很多中形式,注意看源码.
#卷积层
net.conv1 = caffe.layers.Convolution(net.data, kernel_size = 5, num_output = 20,
weight_filler = dict(type = 'xavier'))
# 定义一个卷积层,利用caffe.layers.Coveolution方法.
# net.data为输入,即原始的图像数据.
# kernel_size表示卷积核大小,这里表示5*5.实际上,也可以分开对宽和高进行定义.
# num_output表示特征图的个数,就是blob数据的第二个数量,常用来表示图像的通道数
# weight_filler表示权重的初始化方式,Xavier是一种常用的初始化方式
#池化层
net.pool1 = caffe.layers.Pooling(net.conv1, kernel_size = 2, stride = 2,
pool = caffe.params.Pooling.MAX)
#卷积层
net.conv2 = caffe.layers.Convolution(net.pool1, kernel_size = 5, num_output = 50,
weight_filler = dict(type = 'xavier'))
#池化层
net.pool2 = caffe.layers.Pooling(net.conv2, kernel_size = 2, stride = 2,
pool = caffe.params.Pooling.MAX)
#全连层
net.fc1 = caffe.layers.InnerProduct(net.pool2, num_output = 500,
weight_filler = dict(type = 'xavier'))
#激活函数层
net.relu1 = caffe.layers.ReLU(net.fc1, in_place = True)
# 以上函数的解释可以参见generateDeploy文件.
#全连层
net.score = caffe.layers.InnerProduct(net.relu1, num_output = 10,
weight_filler = dict(type = 'xavier'))
# 类似于一种全连接层,用于计算当前网络的目标值,这还处于前馈网络的环节
# 输出属于0到9的概率,也就是num_output为10
# 权重参数的初始化选择Xavier方式
#softmax层
net.loss = caffe.layers.SoftmaxWithLoss(net.score, net.labels)
# 计算这个深度网络的损失,根据网络得到的输出和label的groundtruth值.
# 这也是一个层,名字为loss,输出值也是loss,利用caffe.layers.SoftmaxWithLoss方式计算.
# 具体的方法可以参考源码,其实就是softmax算法
if include_acc:
net.acc = caffe.layers.Accuracy(net.score, net.labels)
# 建立求准确率层,名字为net.acc,利用caffe.layers.Accuracy
# 需要明白怎样计算准确率的.不过这里比较简单,就是对的个数除以总个数.
return net.to_proto()
return net.to_proto()
# 返回网络的结构,用于写入文件.
# 定义一个将网络写入文件的方式
def write_net(train_proto, train_list, test_proto, test_list):
# 写入prototxt文件
with open(train_proto, 'w') as f:
# 再次提醒,务必要学会with as的用法,可以自动关闭清空内存,还可以捕捉异常
f.write(str(create_net(train_list, batch_size = 64)))
# 通过creat_net函数创建网络结构,并通过str强制转化成字符串写入文件
# 这里batch_size表示一次迭代选择的数据(图片)数量
#写入prototxt文件
with open(test_proto, 'w') as f:
f.write(str(create_net(test_list, batch_size = 100, include_acc = True)))
# 这里写入求准确率的文本,每次选择batch_size(100)个数据进行检测,数据来自与test数据集.
# 注意到训练集的数据和这个测试集的数据不一样.
# 定义一个函数来生成sovler文件.
def write_sovler(my_project_root, solver_proto, train_proto, test_proto):
sovler_string = caffe.proto.caffe_pb2.SolverParameter()
# 利用caffe.proto.caffe_pb2.SolverParameter方法来创建对象
sovler_string.train_net = train_proto
# 指定训练网络
sovler_string.test_net.append(test_proto)
# 指定附加的测试网络
sovler_string.test_iter.append(100)
# 10000/100 测试迭代次数
sovler_string.test_interval = 938
# 60000/64 每训练迭代test_interval次进行一次测试,即设置测试的迭代次数间隔
sovler_string.base_lr = 0.01
# 基础学习率
sovler_string.momentum = 0.9
# 动量, 这是SGD+Monmentum的迭代算法才有的参数
sovler_string.weight_decay = 5e-4
# 指定权重衰减系数
sovler_string.lr_policy = 'step'
# 学习策略,step是一种学习策略,用以改变基础学习率.
sovler_string.stepsize = 3000
# 学习率变化频率,配合上面的学习策略,也就是'step'使用.
sovler_string.gamma = 0.1
# 学习率变化指数,和'step'学习策略相关
sovler_string.display = 20
# 每迭代display次显示一次结果
sovler_string.max_iter = 9380
# 10 epoch 938*10 最大迭代次数
# 注意到迭代次数有很多的相关性
sovler_string.snapshot = 938
# 保存模型的临时迭代数,俗称快照,就是在程序运行过程中,也进行模型的存储
sovler_string.snapshot_prefix = my_project_root + 'mnist'
# 模型快照的绝对地址前缀
sovler_string.solver_mode = caffe.proto.caffe_pb2.SolverParameter.CPU
# 优化模式选择CPU模式还是GPU模式
with open(solver_proto, 'w') as f:
f.write(str(sovler_string))
# 将solver对象以string方式写入文件
# 以下为主函数
if __name__ == '__main__':
current_root = os.getcwd()
# 利用os.getcwd()得到当前目录,这比手动输入要好的多
my_project_root = current_root
# my_project_root = "/home/xml/"
# 定义一个绝对路径前缀,其实就是项目所在的文件夹上一级目录,也就是用户目录
# 可以在命令行中用pwd命令来得到当前目录,后面也会介绍用python的第三方库os来操作
train_list = my_project_root + "/mnist/train/train.txt"
# train.txt文件的位置,可以根据自己的文件目录去修改
test_list = my_project_root + "/mnist/test/test.txt"
# test.txt文件的位置
train_proto = my_project_root + "/train.prototxt"
# 保存train.prototxt文件的绝对位置与名字
test_proto = my_project_root + "/test.prototxt"
# 保存test.prototxt文件的绝对位置与名字
solver_proto = my_project_root + "/solver.prototxt"
#保存solver.prototxt文件的绝对位置与名字
write_net(train_proto, train_list, test_proto, test_list)
print "成功生成train.prototxt和test.prototxt"
# 生成训练网络和测试网络的脚本文件并输出提示消息
write_sovler(my_project_root, solver_proto, train_proto, test_proto)
print "成功生成solver.prototxt"
# 生成solver的脚本文件并输出提示消息
# 还留下一些问题:
# 学习率的构成,调整,不同学习率的作用域及其算法原理
# 学习策略的分类和算法原理
进行训练
# coding: utf-8
# 开始执行训练
# 这里使用IDE端进行训练
# 虽然命令行也可以进行训练,但是一旦出问题就会很很糟糕
# 命令行进行训练,还可以使用sh文件并配合sh命令
# 2018年06月02日17:45:56 于北京
import caffe
import os
# 定义训练的函数
def train(solver_proto):
# 输入是solver文件的绝对目录和文件名.
caffe.set_mode_cpu()
# 指定使用CPU进行训练,如果是GPU,还要指定使用哪个GPU进行训练
solver = caffe.SGDSolver(solver_proto)
# 利用solver文件执行训练
solver.solve()
# 未知,有待分析
# 以下为主文件
current_root = os.getcwd()
# my_project_root = "/home/xml/"
# solver_proto = my_project_root + "learning/mnist/solver.prototxt"
solver_proto = current_root + '/solver.prototxt'
# 指定solver文件的绝对位置,注意里面表示上下级的/符号,要配合好
# 必要时使用pritf进行检查,因为打不开一个文件有时不报错
train(solver_proto)
print ("训练完成")
# 注意到模型文件存在的目录在my_project_root目录下,这点怎么改,还需要学习.
进行单张图片的测试
# -*- coding: UTF-8 -*-
# 利用训练得到的模型,对输入的一张图片(手写数字)进行预测
# 这张图片和训练的图片尺寸相同
import caffe
import numpy as np
import os
def test(my_project_root, deploy_proto):
caffe_model = my_project_root + '/mnist_iter_9380.caffemodel'
# 生成的模型文件的绝对位置和名字(模型中已经包括了各个权重参数)
img = my_project_root + '/mnist/test/0604_1.png'
# 一张待测图片
labels_filename = my_project_root + '/mnist/test/labels.txt'
# 类别名称文件,将数字标签转换回类别名称
net = caffe.Net(deploy_proto, caffe_model, caffe.TEST)
# 加载训练好的模型和预测网络
# deploy_proto表示预测网络
# caffe_model表示训练好的模型
#图片预处理设置
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
# 将图片的shape转化为格式(1,3,28,28)
# 利用caffe.io.Transformer方法进行转化.
# 这里面的细节还需要进一步研究
transformer.set_transpose('data', (2,0,1))
# 改变维度的顺序,由原始图片(28,28,3)变为(3,28,28)
# 利用caffe.io.Transformer的对象的set_transpose方法进行维度的调整
# 将数据维度(0,1,2)变成(2,0,1).后一种模式就是caffe中的blob数据格式(1,3,宽度,高度)
# 其中1表示输入的一张图片,3表示3通道.
transformer.set_raw_scale('data', 255)
# 缩放到【0,255】之间
transformer.set_channel_swap('data', (2,1,0))
# 交换通道,将图片由RGB变为BGR
im = caffe.io.load_image(img)
# 加载图片,也可以用opencv等来完成,这里使用了caffe.io.load_image方法
net.blobs['data'].data[...] = transformer.preprocess('data',im)
# 执行上面设置的图片预处理操作,并将图片载入到blob中
# 将图片转化成caffe的blob数据格式
# 为什么是这样的方式还需进一步学习
out = net.forward()
# 执行测试
labels = np.loadtxt(labels_filename, str, delimiter='\t')
# 读取类别名称文件,里面是10个数字,从0到9,表示图片的分类
prob = net.blobs['prob'].data[0].flatten()
# 取出最后一层(Softmax)属于某个类别的概率值
order = prob.argsort()[-1]
#将概率值排序,取出最大值所在的序号
print '图片数字为:',labels[order]
#将该序号转换成对应的类别名称,并打印
if __name__ == '__main__':
# 这行代码值得讨论一下
# 先不看下划线
# 表示当这整个代码被运行时,这个模块名字为main,下面的代码会被运行
# 如果整个代码被当做模块引入其他代码时,本代码的模块就不为main了,以下代码就不会被运行.
# 简单了解可参考:https://blog.csdn.net/duanboqiang/article/details/52921819
# 详细了解请查考:http://blog.konghy.cn/2017/04/24/python-entry-program/
# 这里留意以下__name__和__main__的用法,其实身边很多人讲不清这个用处.只知道这时python的内置方法或者函数.
my_project_root = os.getcwd()
#my-caffe-project目录
deploy_proto = my_project_root + "/deploy.prototxt"
#保存deploy.prototxt文件的位置
test(my_project_root, deploy_proto)
进行多张图片的测试并计算准确率
# -*- coding: UTF-8 -*-
# 利用训练得到的模型,对输入的多张图片(手写数字)进行预测
# 为了测试在很多新数据下的准确率
# 所有图片格式和训练图片相同
# 2018年06月04日02:00:58
# 这里需要测试的图片及文本信息放置的位置在函数test中,其实并不是很好,应该设计成主函数的一个形参
import caffe
import numpy as np
import os
# 定义一张图片的预测函数
# 输入:
# my_project_root 当前项目的根目录
# deploy_proto 预测模型(绝对路径)
# # testFile 需要检测准确率的文件数据(包含图像名称和数据)
# 将预测错误的信息写入一个文件
def test(my_project_root, deploy_proto):
caffe_model = my_project_root + '/mnist_iter_9380.caffemodel'
# 生成的模型文件的绝对位置和名字(模型中已经包括了各个权重参数)
falseFile = my_project_root + '/falsePredict.txt'
writeFalseResult = open(falseFile,'w+')
# 打开一个文件,里面将会写入预测错误的图片及其相关信息,包括图片名称,正确的label,错误的label(按照顺序)
numberOfImage = 0
# 记录测试了多少张图片
rightNumber = 0
# 记录正确预测的个数
filesToPredict = my_project_root + '/mnist/test/test.txt'
with open(filesToPredict) as f:
for lines in f.readlines():
numberOfImage += 1
img = lines.split()
imgName = img[0]
# print(imgName)
imgLabel = img[1]
# 考虑到程序健壮性,这里应该判断是否有这个数据.
img = my_project_root + '/' +imgName
# 一张待测图片
labels_filename = my_project_root + '/mnist/test/labels.txt'
# 类别名称文件,将数字标签转换回类别名称
net = caffe.Net(deploy_proto, caffe_model, caffe.TEST)
# 加载训练好的模型和预测网络
# deploy_proto表示预测网络
# caffe_model表示训练好的模型
# 图片预处理设置
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
# 将图片的shape转化为格式(1,3,28,28)
# 利用caffe.io.Transformer方法进行转化.
# 这里面的细节还需要进一步研究
transformer.set_transpose('data', (2, 0, 1))
# 改变维度的顺序,由原始图片(28,28,3)变为(3,28,28)
# 利用caffe.io.Transformer的对象的set_transpose方法进行维度的调整
# 将数据维度(0,1,2)变成(2,0,1).后一种模式就是caffe中的blob数据格式(1,3,宽度,高度)
# 其中1表示输入的一张图片,3表示3通道.
transformer.set_raw_scale('data', 255)
# 缩放到【0,255】之间
transformer.set_channel_swap('data', (2, 1, 0))
# 交换通道,将图片由RGB变为BGR
im = caffe.io.load_image(img)
# 加载图片,也可以用opencv等来完成,这里使用了caffe.io.load_image方法
net.blobs['data'].data[...] = transformer.preprocess('data', im)
# 执行上面设置的图片预处理操作,并将图片载入到blob中
# 将图片转化成caffe的blob数据格式
# 为什么是这样的方式还需进一步学习
out = net.forward()
# 执行测试
labels = np.loadtxt(labels_filename, str, delimiter='\t')
# 读取类别名称文件,里面是10个数字,从0到9,表示图片的分类
prob = net.blobs['prob'].data[0].flatten()
# 取出最后一层(Softmax)属于某个类别的概率值
order = prob.argsort()[-1]
# 将概率值排序,取出最大值所在的序号
print '图片数字为:', labels[order]
# 将该序号转换成对应的类别名称,并打印
if labels[order]==imgLabel:
# 判断是否预测正确
rightNumber += 1
else:
result = imgName + ' ' + imgLabel + ' ' + str(labels[order])
writeFalseResult.write('{}\n'.format(result))
# 如果没有预测正确,则将图片名称信息,图片正确的label,预测的分类依次写入对应文件中
# 其中,\n表示换行操作
if numberOfImage > 0:#需要一个防止分母为0的情况,提高程序的健壮性
print '正确的张数为', rightNumber
print '共测试图片', numberOfImage, '张'
# 输出正确率的统计值
print '准确率为', 100. * rightNumber/numberOfImage, '%'
# 注意如果这里不是100.,也就说不加100后的小数点,有时数据量大时,正确率不是1,而会变成0的成功率
# 此外还要注意到,100.放在最后也是不行的,因为前面的运算使得数为整形,变成了0,再乘以100.成为小数,也是0.0而已
writeFalseResult.close()
# 一定要记得关闭写文件的内存,养成这样的习惯
if __name__ == '__main__':
# 这行代码值得讨论一下
# 先不看下划线
# 表示当这整个代码被运行时,这个模块名字为main,下面的代码会被运行
# 如果整个代码被当做模块引入其他代码时,本代码的模块就不为main了,以下代码就不会被运行.
# 简单了解可参考:https://blog.csdn.net/duanboqiang/article/details/52921819
# 详细了解请查考:http://blog.konghy.cn/2017/04/24/python-entry-program/
# 这里留意以下__name__和__main__的用法,其实身边很多人讲不清这个用处.只知道这时python的内置方法或者函数.
my_project_root = os.getcwd()
# 项目根目录
deploy_proto = my_project_root + "/deploy.prototxt"
# 保存deploy.prototxt文件的位置
test(my_project_root, deploy_proto)
一个方便大家的博客怎能没有训练数据!
并请将数据下载后解压到当前项目文件夹
mnist数据下载:链接: https://pan.baidu.com/s/1xBCi3mHY743d2hM_jvYH1Q 密码: ihew
后续会进一步分析一些问题:
# caffe中各个文件的区别,训练网络,测试网络,与预测网络三者的区别。
# 总结每个层的作用,区别,原理,代码中的定义方式
# caffe中各个文件的区别,训练网络,测试网络,与预测网络三者的区别。
# 为什么caffe的一些函数和方法不能自动补全?
# 如何可视化网络框架
# 总结每个层的作用,区别,原理,代码中的定义方式
|